Persistence layer considered in the context of this thesis should be able to manipulate persistent instances of certain classes. These classes are called persistent classes, its instances persistent objects. Storing objects to database implies that the layer should store their attribute values to underlying database structures. Because all predecessors of this thesis used relational database systems as their persistent storage, let's focus first on this area first.
Persistent classes would be represented as tables and their attributes as their columns. Instances of persistent classes would be inserted into these tables as rows containing instance attribute values associated with corresponding table columns. Basic requirements on a persistence library could be:
Ability to associate persistent classes with database tables
Ability to map attributes of these classes on columns in associated tables. This means that the layer should be able to store attributes of certain C++ types (basic numeric types, strings) into the database as column values.
Classes can also contain attributes of structured types or collections, which are often mapped into separate tables or split into more columns in the relational model.
Last attribute type to be discussed is an association (C++ pointer/reference). Association can be modelled using foreign key relationship between matching tables. The persistence layer should be able to handle single associations as well as collections of associations.
An optional requirement may be an ability to generate required database schema in form of a SQL create (or drop) script. The persistence layer may require its own structures in the underlying database or it may be able to operate upon existing database schema.
Ability to query subsets of object model content. The layer should provide a query language that would abstract from the physical representation of the object model in the database.
Up to now we have considered only single classes without inheritance relations. However, in C++ classes can form complex inheritance hierarchies and it is a natural requirement to be able to store descendants of persistent classes too. There are several ways how to store these hierarchies into a relational database.Figure 2.1, “Example class hierarchy” contains an example hierarchy on which we will demonstrate these mapping types. This hierarchy will also be used and modified further in the text.

Vertical mapping is a most common (and natural) way of mapping attributes of persistent classes in an inheritance hierarchy into tables in a relational database. Each class in this hierarchy has one associated table in the database. Values from attributes declared in correspondent classes only are stored into these tables. This means that attributes declared in current class are mapped into its associated table, attributes from parent class are mapped into its "parent" table etc. Storing one object invokes a cascade of database inserts. Similar rules apply for updates, deletes and selects. However, selects can be simplified by using table joins and database views. This solution offers good performance for shallow hierarchies, which is getting worse with the inheritance graph getting deeper. It is a best choice for scenarios where polymorphism does matter - by querying one table we easily get instances of associated class and its descendants.
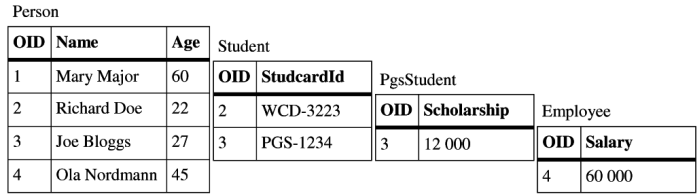
Let's consider following instances of the classes from Figure 2.1, “Example class hierarchy”:
Student(name: "Richard Doe", age: 22, studcardid: "WCD-3223") PhdStudent(name: "Joe Bloggs", age: 27, studcardid: "PHD-1234", scholarship: 12000) Employee(name: "Ola Nordmann", age: 45, salary: 60000) Person(name: "Mary Major", age: 60)
Vertical mapping will spread data from these instances into four tables as illustrated in the Figure 2.2, “Vertical mapping tables”. The tables are arranged so that attribute values belonging to one particular class are displayed in the same row. To be able to join data from the tables we use surrogate OID as explained in the previous chapter. All rows belonging to one particular object are assigned the same OID.
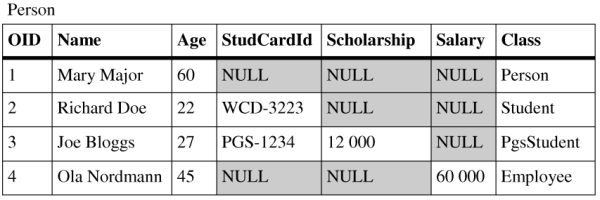
Horizontal mapping offers better performance for scenarios where we don't need polymorphic queries - accessing descendants of specific class. Again, each persistent class in a hierarchy has one associated table into which its instances store their attributes. The difference from vertical mapping is that these tables contain even attributes inherited from parent persistent classes. Rows in these tables contain enough information to load complete persistent class instances, thus no cascade operations are needed. Every instance of horizontally mapped class is mapped only into one table row in the database.

As you can see in Figure 2.3, “Horizontal mapping tables” - queries using polymorphism can be very hard to perform. Finding a specific object of Person type or its descendants involves looking into all the tables. However, opposite to the vertical mapping, if we work with objects of specific type (not including descendants), we don't need any joins in select statements or cascade inserts/updates.
Filtered mapping assigns only one database table to all persistent classes in one inheritance hierarchy - see Figure 2.4, “Filtered mapping tables”. This table contains columns that represent all attributes from all classes in that hierarchy. Filtered mapping doesn't suffer from disadvantages of two previous approaches - it performs very well on polymorphic data and doesn't involve cascaded operations/joins. A disadvantage of this approach is excessive storage requirement. Most of the rows in the table will contain empty cells in columns that belong to attributes from descendants or from classes not being in ancestor relationship of the matching class (for example the column Scholarship in the "Ola Nordmann" row. Second thing is that it is necessary to add a column telling us which class the rows belong to. As we have all rows in one table there is no other easy way how to distinguish the instance types.
Combined mapping is a combination of mappings mentioned above. It allows users to use all kinds of mappings in one inheritance hierarchy. Combined mapping is the most sophisticated variation that allows users to specify these mappings according to their needs. It is also quite complex for implementation, it has some constraints how the mapping types can be used and it is not well maintainable on the database side. Database structures created for combined mapping would require nontrivial constraints if their content was modified other way than using the persistence layer that created the structures. The persistence layer should hide this complexity beyond views to provide at least convenient read-only access. To see how the combined mapping can be used refer to Figure 2.5, “Combined mapping tables”.
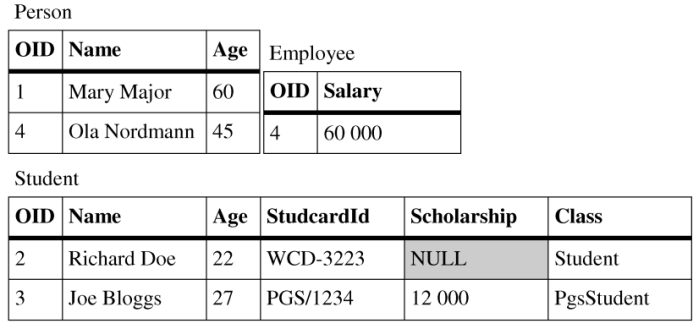
The Employee class uses vertical mapping, the Student class uses horizontal mapping and the PhdStudent class uses filtered mapping. Classes that use filtered mapping can choose into which of their ancestors thir attributes will be mapped. Class PhdStudent is mapped to the table belonging into the Student class.