All mapping types offered by the IOPC library are also implemented in the IOPC 2 library - horizontal, vertical, filtered as well as combinations of them. IOPC 2 library provides as much freedom combining them within one inheritance hierarchy as the IOPC library does. Additionally, ADT mapping is available for use with object-relational databases. Developers can combine ADT mapping with the other mapping types under certain restrictions.
IOPC 2 offers most of its functionality if using a generated schema with surrogate keys (OID columns) and OID objects. Such schema contains additional views, tables or types which support the mapping process. IOPC 2 also handles existing schemas with no OID columns or additional database structures as well. It is able to map data from read-only databases or from aggregated query results into standard persistent objects.
Detailed aspects of the object-relational mapping implementation are discussed in the following sections.
Figure 4.2, “IOPC 2 base classes” displays base class hierarchy for persistent classes defined in IOPC 2. Data classes in user applications should derive from one of these supertypes. Each of these base classes provides different level of functionality for its descendants.
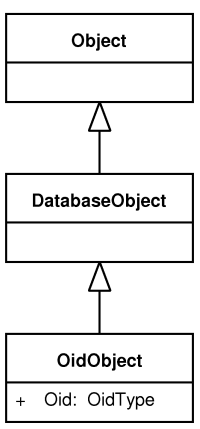
The Object descendants are capable of reflection. The reflection mechanism inspects descendants (direct or indirect) of this class only. Reflection is database independent and can be used separately as a standalone part of the IOPC 2 library. This also implies that direct descendants cannot be persisted. Persistence is provided for DatabaseObject and OidObject descendants.
DatabaseObject descendants are persistent classes that describe identity of their instances as a list of key attributes. Database objects do not necessarily need to have any identity defined as they may represent for example aggregate query results as described in the section called “The identity of persistent objects”. DatabaseObjects with the key attributes defined can be mapped into database tables. They even support vertical and horizontal database mapping. However, the subclasses have to share the same set of key attributes. This enables inheritance, but polymorphism is somewhat limited as IOPC 2 is not capable of recovering the effective type of an object from a set of key attribute values. IOPC 2 does not generate structures for classname resolution based on the key values, so when loading an object identified by its key values, the type of the loaded object must be specified. That is also the reason why filtered mapping is not supported for non-OID objects.
Example 4.4. DatabaseObject usage
class Person : public iopc::DatabaseObject {
public:
EString name;
EString idcard;
EString country;
static void iopcInit(iopc::Type& t) {
t.getAttribute("idcard")["db.primaryKey"].setBoolValue(true);
t.getAttribute("country")["db.primaryKey"].setBoolValue(true);
}
};
class Student : public Person {
public:
EString studcardid;
};
Class hierarchy in Example 4.4, “DatabaseObject usage” shares two key attributes - idcard and country. The IopcInit static method is invoked by the reflection mechanism when the program starts. Usually it creates class metadata[22] modifying the database mapping behaviour of this class or of its attributes. In this case it tells the library which attributes are parts of the class composite key. In the generated SQL schema (using the default vertical mapping), all table definitions include the two corresponding key columns - see Example 4.5, “SQL schema generated for DatabaseObject subclasses.”.
Example 4.5. SQL schema generated for DatabaseObject subclasses.
CREATE TABLE Person ( country VARCHAR2(2000), idcard VARCHAR2(2000), name VARCHAR2(2000), CONSTRAINT Person_pk PRIMARY KEY (idcard, country)); CREATE TABLE Student ( studcardid VARCHAR2(2000), idcard VARCHAR2(2000), country VARCHAR2(2000), CONSTRAINT Student_pk PRIMARY KEY (idcard, country));
OidObject guarantees an identity in form of an internally generated OID to all of its descendants. Unique OID is assigned to any instance of an OidObject descendant at its creation time and remains unchanged during its lifetime. OidObject descendants are able to use all types of database mappings. Oid objects depend on database structures generated by the IOPC 2 library. These structures include simple or polymorphic views (as in the original IOPC library - see the section called “IOPC DBSC”) or an Oid - classname catalogue. The catalogue is actually a regular mapping table associated with the OidObject class. Each OID object in the database is represented by a row in the catalogue regardless of the mapping type used. The catalogue table has three columns - OID, CLASSNAME (qualified name of the class this row - OID - belongs to) and SERIALID (timestamp used by the cache layer).
Example 4.6, “SQL schema generated for OidObject subclasses.” contains schema generated for the classes from the earlier Example 4.1, “Basic persistent class definition in IOPC 2”. Note that code of all SQL examples below is generated by the Oracle 10g driver. Source code of associated views can be found in Appendix B, Sample schema SQL scripts.
Example 4.6. SQL schema generated for OidObject subclasses.
-- the oid - classname catalogue CREATE TABLE OidObject ( CLASSNAME VARCHAR2(1000), OID NUMBER(10), SERIALID NUMBER(10), CONSTRAINT OidObject_pk PRIMARY KEY (OID)); -- mapping tables (using vertical mapping) CREATE TABLE Person ( age NUMBER(5), name VARCHAR2(2000), OID NUMBER(10), CONSTRAINT Person_OID_fk FOREIGN KEY (OID) REFERENCES OidObject(OID) CONSTRAINT Person_pk PRIMARY KEY (OID)); CREATE TABLE Student ( studcardid VARCHAR2(2000), supervisor NUMBER(10), OID NUMBER(10), CONSTRAINT Student_OID_fk FOREIGN KEY (OID) REFERENCES OidObject(OID) CONSTRAINT Student_pk PRIMARY KEY (OID)); CREATE TABLE PhdStudent ( scholarship NUMBER(5), OID NUMBER(10), CONSTRAINT PhdStudent_OID_fk FOREIGN KEY (OID) REFERENCES OidObject(OID) CONSTRAINT PhdStudent_pk PRIMARY KEY (OID)); CREATE TABLE Employee ( salary NUMBER(10), OID NUMBER(10), CONSTRAINT Employee_OID_fk FOREIGN KEY (OID) REFERENCES OidObject(OID) CONSTRAINT Employee_pk PRIMARY KEY (OID));
ADT mapping, as described in the section called “Object-relational databases”, is a new type of database mapping introduced in the IOPC 2 library. It requires the underlying DBMS to support definition of user defined abstract data types (ADT).
ADT mapping can be used with some restrictions. First, only OID objects can be marked for use with the ADT mapping type. Because structures required for this kind of mapping are generated by the library and will surely not be reused from existing schema, there is no reason why not to use OID objects. Working with OID objects is convenient and also faster than any other alternative. Second, ADT mapping is meant to be used for whole hierarchies of classes and thus no other mapping type can be used in any of their descendants. In contrast, ADT mapping hierarchy can be started at any level of inheritance tree of classes with other mapping type.
This leads to several ways of how to use ADT mapping, which should be considered when designing classes and data model.
One ADT hierarchy for all persistent classes in the application. It also means one table for all types and all classes. This can be achieved by telling the root of all OID objects (the
OidObjectclass) to use ADT mapping.One ADT hierarchy per top-level class. Top-level classes (direct descendants of
OidObject) use the ADT mapping type. These classes and all of their descendants are stored in separate tables and are represented by separate ADT hierarchies.OidObjectis mapped into a separate relational table containing all object OIDs .ADT hierarchy started at a lower level of persistent class hierarchy. Ancestors of an ADT-mapped type can use any other type of database mapping. The base ADT definition consists of the OID attribute and attributes defined in the corresponding class. Therefore the base ADT table has same structure as if the class used vertical mapping. The horizontal approach (all inherited attributes in the ADT definition) can be considered in the future.
Example 4.7, “Using the ADT mapping.” shows how the ADT mapping can be set for the Student and PhdStudent classes and leaving its parent Person and the class Employee to use the default vertical mapping. Note, that the ADT mapping type is denoted by the code "object" in the IOPC 2 library.
Example 4.7. Using the ADT mapping.
class Person : public iopc::OidObject {
public:
EShort age;
EString name;
};
class Employee : public Person {
public:
EInt salary;
};
class Student : public Person {
public:
EString studcardid;
DbPtr<Employee> supervisor;
static void iopcInit(iopc::Type& t) {
t["db.mapping.type"].setStringValue("object");
}
};
class PhdStudent : public Student {
public:
EShort scholarship;
static void iopcInit(iopc::Type& t) {
t["db.mapping.type"].setStringValue("object");
}
};
This time we specify the class metadata db.mapping.type to change the mapping type of the two classes to ADT mapping. Example 4.8, “SQL schema from classes that use ADT mapping.” displays an excerpt from the generated SQL schema.
The static methods insert_object, update_object and delete_object are used by IOPC 2 to insert, modify or delete the ADT instances. Constructors could not be used because Oracle 10g does not allow specifying their parameters in arbitrary order as required by the library.
Example 4.8. SQL schema from classes that use ADT mapping.
CREATE TABLE Person (
age NUMBER(5), name VARCHAR2(2000), OID NUMBER(10),
CONSTRAINT Person_pk PRIMARY KEY (OID),
CONSTRAINT Person_OID_fk FOREIGN KEY (OID) REFERENCES OidObject(OID));
CREATE OR REPLACE TYPE tStudent AS OBJECT (
OID NUMBER(10), supervisor NUMBER(10), studcardid VARCHAR2(2000),
STATIC PROCEDURE insert_object(
p_OID NUMBER, p_studcardid VARCHAR2),
STATIC PROCEDURE update_object(
p_OID NUMBER, p_studcardid VARCHAR2),
STATIC PROCEDURE delete_object(
p_OID NUMBER)
) NOT FINAL;
CREATE OR REPLACE TYPE tPhdStudent UNDER tStudent (
scholarship NUMBER(5),
STATIC PROCEDURE insert_object(
p_OID NUMBER, p_studcardid VARCHAR2, p_scholarship NUMBER),
STATIC PROCEDURE update_object(
p_OID NUMBER, p_studcardid VARCHAR2, p_scholarship NUMBER),
STATIC PROCEDURE delete_object(
p_OID NUMBER)
) NOT FINAL;
CREATE TABLE Student OF tStudent (
CONSTRAINT Student_pk PRIMARY KEY (OID),
CONSTRAINT Student_OID_fk FOREIGN KEY (OID) REFERENCES OidObject(OID));
The mapping algorithm operates with several lists of classes and attributes which are pre-created at the start of a user application. These lists are generated for all persistent classes - descendants of the DatabaseObject class.
AllParents- a list of ancestor classes that have a corresponding database table. This includes only classes that use horizontal or vertical mapping. Classes that use filtered mapping do not have any associated database table as their columns are inserted into one of their ancestors. Because ADT-mapped classes are handled in a different way, they are not inserted into this list either. The list represents tables that will be accessed when performing a CRUD operation on an instance of the current class. Only one database operation is needed to modify database data belonging to an instance of any class in an ADT-mapped class subgraph. See the examples at the end of this section and also refer to the mapping algorithm description.The list is created by level-order walking through the parent hierarchy starting with parents of the current class first. If the process encounters a horizontally-mapped class, its parents are not processed (because horizontally-mapped classes store all, even inherited attributes into one table). If the current class derives from
OidObject, and ifOidObjectdoes not use ADT mapping,OidObjectis also appended to this list.FilteredTypes- list of classes that use table associated with the current class as a destination for their attributes when filtered mapping is used. Note that there must be at least one path between the source and destination classes in the inheritance hierarchy that does not contain a horizontally-mapped class.PersistentAttributes- list of persistent attributes declared in the current class. Developers may declare some of the class attributes as transient. Transient attributes are ignored by the persistence layer.KeyAttributes- list of key attributes that are inherited or declared in the current class. If the current class derives fromOidObject, the OID attribute is included in the list. A class cannot re-define key attributes if they were already defined in one of its ancestors.InheritedAttributes- list of persistent attributes (retrieved fromPersistentAttributes) inherited from all persistent ancestors.AllPersistentAttributes- union of thePersistentAttributesandInheritedAttributeslists.MappedAttributes- list of attributes that are physically mapped into table associated with the current class. In fact they represent columns of this table. The list may include attributes from other classes. Attributes are categorized by their origin:Persistent attributes of the current class. (
PersistentAttributes)If the current class uses horizontal mapping, the list includes non-key inherited persistent attributes from the
InheritedAttributeslist. Attributes inherited from theOidObjectare excluded as the Oid - classname catalogue (a table associated withOidObject) is accessed even when using horizontal mapping.Persistent attributes from classes that use filtered mapping - persistent attributes from classes in the
FilteredTypeslist.Inherited
KeyAttributes- even if the class does not employ horizontal mapping.
This list is not generated for classes that use ADT mapping.
To understand how the lists are generated, see the following examples. First, lists generated for the default scenario - all persistent classes use vertical mapping. Lists for the Student class:
AllParents:Person,OidObjectFilteredTypes: no membersPersistentAttributes:studcardid,supervisorKeyAttributes:oidInheritedAttributes:oid,serialid,classname(all fromOidObject),name,ageAllPersistentAttributes:oid,serialid,classname(all fromOidObject),name,age,studcardid,supervisorMappedAttributes:oid(key),studcardid,supervisor(regular columns)
Second, the class Student uses horizontal mapping and PhdStudent uses filtered mapping to map its attributes to table associated with the Student class. Only the contents of the AllParents, MappedAttributes and FilteredTypes lists would change:
AllParents:OidObjectFilteredTypes:PhdStudentPersistentAttributes:studcardid,supervisorKeyAttributes:oidInheritedAttributes:oid,serialid,classname(all fromOidObject),name,ageAllPersistentAttributes:oid,serialid,classname(all fromOidObject),name,age,studcardid,supervisorMappedAttributes:oid(key),studcardid,supervisor(regular columns),age,name(inherited columns),scholarship(filtered column)
Schema generated for this scenario would look like this:
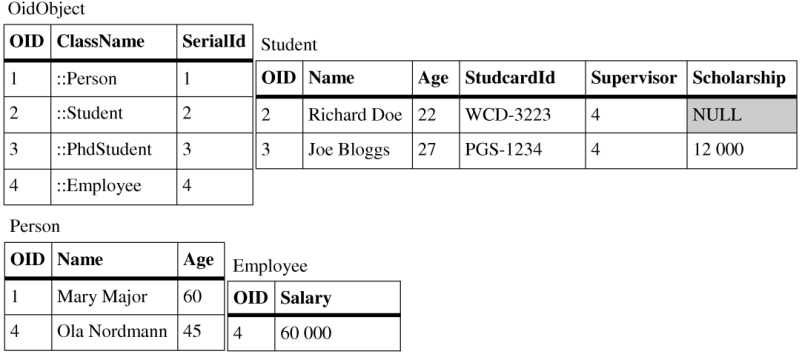
As you may see, there is no PhdStudent table as all its columns were appended to the Student table. As a result of the horizontal mapping, rows belonging to these two classes do not have entries in the Person table.
And the last example - classes from the previous section. ADT mapping is enabled for Student and its PhdStudent descendant, see Example 4.7, “Using the ADT mapping.” for the class model definition. This time, the lists for the PhdStudent class:
AllParents:Person,OidObjectFilteredTypes: no membersPersistentAttributes:scholarshipKeyAttributes:oidInheritedAttributes:oid,serialid,classname(all fromOidObject),name,age,studcardid,supervisorAllPersistentAttributes:oid,serialid,classname(all fromOidObject),name,age,studcardid,supervisor,scholarshipMappedAttributes: not generated.
In this section, we will describe the algorithm for CRUD operations performed by the IOPC 2 persistence layer. First, the top-level part of the algorithm for inserting, updating and deleting persistent objects is described.
Given an object O, the algorithm iterates through its parent class hierarchy (starting with the class of O itself) and calls one of the Insert_Row() or Insert_Object() methods on it (depending on which mapping type is used). The Insert_Row method is described in Figure 4.5, “Description of the Insert_Row method. Not used for ADT mapping.”. Update_Row or Delete_Row methods have similar structure.
Figure 4.4. Top-level part of the object-relational mapping algorithm
if O uses ADT mapping thenInsert_Object(O) // Update_Object or Delete_Object else if O uses horizontal or vertical mapping (O has a corresponding db table) then
Insert_Row(O, class of O) // Update_Row or Delete_Row end if foreach class C in AllParents do
Insert_Row(O, C) // Update_Row or Delete_Row end
First, the algorithm handles either the whole subgraph of ADT mapping classes (as they are stored as one ADT instance at a time) | |
or the class of the object being inserted (if it has its own associated database table). | |
Then it iterates through ancestors of the objects' class and inserts values of attributes defined in them into a new database row. |
Figure 4.5. Description of the Insert_Row method. Not used for ADT mapping.
Insert_Row(object O, class C):
foreach attr A in C.MappedAttributes
if A is not filtered attribute [category 1, 2, 4]
insert value of O.A into the new db row
else -- filtered attribute [category 3]
if class of O is descendant of class containing the attribute A
insert value of O.A from O into the new db row
else
insert NULL as attribute A into the new db row
end if
end if
end
The method iterates through attributes (or actually columns of the associated table to the class C) and inserts values to a new row. The process is quite self-explanatory except for filtered attributes (category 3). If a class has two descendants that use filtered mapping as shown in the Figure 4.6, “Inserting objects using filtered mapping”, a row representing an instance of class A (or its descendant) will contain NULLs in columns of attributes from class B and vice versa. Condition that solves this issue is marked (1) in the algorithm.

The table in Figure 4.6, “Inserting objects using filtered mapping” further illustrates the need for classes that use filtered mapping to derive from OidObject. When loading an object with OID "1", the object-relational layer has to know which class to instantiate and only OidObject provides such database structures that provide this information.
Same algorithm as in Figure 4.5, “Description of the Insert_Row method. Not used for ADT mapping.” is used for storing changes from objects that already have a database identity (Update_Row method). Changes are propagated as SQL UPDATEs with the WHERE generated from list of KeyAttributes and their values. For OID objects this means that the WHERE filters only by the objects' OID value. Condition (1) from the algorithm is slightly modified in a way that no NULLs are inserted but simply the NULL-attributes are not updated. Deleting data is a trivial case - Delete_Row sends one SQL DELETE command to delete the requested row. The DELETE command uses same WHERE clause as the UPDATE does.
You can see that most of the work is done by correctly pre-generating the lists from the previous section, in particular the MappedAttributes and AllParents lists. They actually contain projection of the class model on the database structures according to the mapping types used.
As for the ADT mapping, the algorithm for inserting, updating or deleting is even simpler (see (1) in Figure 4.4, “Top-level part of the object-relational mapping algorithm”). IOPC 2 relies on the object-relational features provided by the underlying database. Insert operation usually creates a new instance of relevant ADT and inserts it into a ADT hierarchy base table[23]. Moreover, due to significant differences between DBMSs in the area of object-relational features, most of the work is delegated to the database driver side. IOPC 2 database drivers are responsible for generating the needed database structures including the ADTs. The library does not take any special steps to support multiple inheritance, so it is fully in charge of the database driver. If the ORDBMS does not support multiple inheritance of ADTs, it does not make much sense to bend the database engine to support it.
Example 4.8, “SQL schema from classes that use ADT mapping.” in the section called “ADT mapping” discussing ADT mapping illustrates how the needed database structures may look like. If we assume that these database structures are already created, inserts, updates and deletes are reduced to simple calls to the database access layer. If using the Oracle 10g database driver, these calls are only delegated further to the insert_object, update_object or delete_object static methods of corresponding ADTs.
The only additional task the ADT mapping requires is to decide which persistent class attributes will be mapped to ADTs. The simplest scenario is if all of the persistent classes starting with OidObject use ADT mapping - all attributes will be mapped to corresponding ADTs and point (3) in the general algorithm (Figure 4.4, “Top-level part of the object-relational mapping algorithm”) will be skipped. However, if the ADT mapping hierarchy is started at a lower level and derives for example from a class that uses vertical mapping, the attributes defined in classes "above" the root(s) of the ADT mapping hierarchy must be skipped and must not be propagated to the corresponding ADTs (as described in the section called “ADT mapping”).
Figure 4.7, “Iterative loading algorithm” illustrates how object instances are loaded from database.
Figure 4.7. Iterative loading algorithm
if O uses ADT mapping Load_Object(O) else if O uses horizontal or vertical mapping (O has a corresponding db table) then Load_Row(O, class of O) end if foreach class C in AllParents do Load_Row(O, C) end
The algorithm is very similar to the previous one (Figure 4.4, “Top-level part of the object-relational mapping algorithm”). Retrieving instances in such way - class by class - is quite inefficient. The algorithm can be implemented as pre-generated views executing queries that join the involved tables. The views (simple and polymorphic views) are generated for descendants of OidObject. Instead of sending multiple SELECTs to retrieve data directly form the mapping tables, only one SELECT executed on a simple view is sufficient. The algorithm just loads values of AllPersistentAttributes from corresponding simple view. Source code of these views can be found in Appendix B, Sample schema SQL scripts.
Iterative algorithm (without views) is used for classes that derive from DatabaseObject (and not from OidObject) and for instances that are requested to be exclusively locked in database. Rows belonging to such instances must be locked one-by-one usually by sending SELECT FOR UPDATE statements.
Modifying these views to be updatable for inserts, updates and deletes was considered, but not included into this release. Current DBMSs place many restrictions on the way how updatable views should be constructed and used. Most of them etirely disallow using joined tables in updatable views; Oracle for example supports updatable join views, but allows only columns from one table to be updated at a time[24].
Again, loading instances of classes that use ADT mapping is a very simple task. In both Oracle and DB2, single SELECT statement can load all attributes of an ADT. If all classes of our example class model used ADT mapping, a SELECT statement to load a single Student instance would look like Example 4.9, “Loading objects using ADTs from an Oracle database”.
Example 4.9. Loading objects using ADTs from an Oracle database
SELECT TREAT(VALUE(X) AS tStudent).OID AS OID, TREAT(VALUE(X) AS tStudent).CLASSNAME AS CLASSNAME, TREAT(VALUE(X) AS tStudent).age AS Person_age, TREAT(VALUE(X) AS tStudent).name AS Person_name, TREAT(VALUE(X) AS tStudent).studcardid AS Student_studcardid, TREAT(VALUE(X) AS tStudent).supervisor AS Student_supervisor FROM OidObject O WHERE O.OID = 2;
Because, as mentioned before, ADT mapping hierarchies can be started at lower level and its roots can derive from non-ADT-mapped classes, either iterative algorithm from the section called “Loading objects from database” or pre-generated views are used to retrieve object instances from database.