Metamodel description is created for all descendants of the Object class. Source files must be processed using iopcsp and the result must be compiled and linked together with the iopcmeta library and the user application. The metamodel can be then inspected using classes and structures defined in iopcmeta.
Figure 5.5, “The iopcmeta classes” provides an overview of these classes.
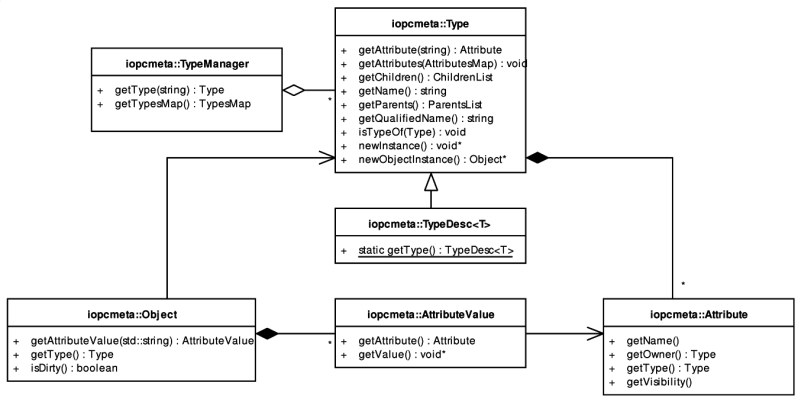
The Type class and its descendant, the TypeDesc<T> template class, are the central point of the reflection mechanism. Instances of the TypeDesc<T>specializations represent reflection-capable classes and all basic C++ types. There is only one instance of the template specialization for a reflection-capable class or a basic type. As mentioned before, the concept is similar to prototypes in the POLiTe libraries and to IopcClassObjectImpl from the IOPC library. However, classes defined in iopcmeta do not provide any object-relational mapping capabilities.
The TypeDesc<T> template class uses technique called type traits to encapsulate various type-dependent data and to provide access to the metamodel description at compile-time in a static way. For example, given the class User, the correspondent type trait is TypeDesc<User> and the solitary type instance is accessible via the TypeDesc<User>::getType() call. Type traits are defined in a manner illustrated in Example 5.2, “Type traits”. As you can see, this is a good way how to unify the metamodel interface for C++ basic types along with the object types declared in the IOPC 2 library.
Example 5.2. Type traits
// Generic template
template<typename T>
class TypeDesc : public Type {
public:
virtual const std::string getName() const;
...
}
// Template specializations for particular types
template<>
class TypeDesc<int> : public Type {
virtual const std::string getName() const { return "::int"; }
}
template<>
class TypeDesc<Object> : public Type {
virtual const std::string getName() const { return "iopc::Object"; }
}
TypeManager is a singleton class which maintains a list of instances of the Type subclasses. As the call to TypeDesc<T>::getType() is a method how to gain access to the metamodel in a static way, the call to TypeManager::getType(std::string typeName) can be used to obtain the type information from a run-time constructed type-name string.
The Object class as a predecessor of all reflection-capable classes does not offer much functionality. It provides infrastructure for dirty status tracking and a list of AttributeValue objects that allow developers to modify object attribute values using reflection. This leads us to the Attribute class whose instances represent attributes of a particular class. Object also contains a getType() method which is the last way leading us to the corresponding Type instance.
Example usage of reflection can be found in Example 5.3, “Using the reflection interface”. The example prints a brief description of the Person class we defined earlier. For more examples, see the section called “Inspecting objects with reflection”.
Example 5.3. Using the reflection interface
const Type& t = TypeDesc<Person>::getType();
cout << "Type name: " << t.getQualifiedName() << endl;
cout << "Attributes: " << endl;
const Type::AttributesMap& attributes = t.getAttributes();
for(Type::AttributesIterator it = attributes.begin(); it != attributes.end(); it++) {
cout << it->first << ": " <<
it->second.getType().getQualifiedName() << endl;
}
// For simplicity we assume that multiple inheritance
// is not used
cout << "Parent: " << t.getFirstParent().getQualifiedName() << endl;
cout << "Children: " << endl;
const Type::ChildrenList& children = t.getChildren();
for(Type::ChildrenIterator it = children.begin(); it != children.end(); it++) {
cout << (*it)->getQualifiedName() << endl;
}
// Output is:
Type name: ::Person
Attributes:
age: iopc::EShort
name: iopc::EString
Parent: iopc::OidObject
Children:
::Employee
::Student
Mostly because of the need of dirty status tracking for the object-relational layer a set of classes encapsulating C++ built-in types was created. The basic requirement is that starting from a specific time, an object needs to be aware if value of any of its attributes has been changed. There are several transparent ways how to fulfil this requirement (like preserving a copy of the object and comparing it with the original when needed) and one of the simplest is to have the attributes to be aware of their own changes. This is achieved in the library by creating new data types that mimic behaviour of built-in types. These types are called enhanced data types. Developers are, however, not forced to use these types, they can use built-in types and manually notify the object that its state has changed.
POLiTe libraries solved this problem by using setter methods generated from descriptive macros. The additional task of the setter methods is simply to modify the dirty status flag of the containing object. IOPC library took advantage of the OpenC++ parsers' ability to process entire source code and changed every relevant assignment operation to use generated setter methods similar to the POLiTe ones.
Second goal was to create a common interface for data types of class attributes that will unify the way how they are mapped to the database. Thanks to enhanced data types, string values, numeric values or references to other objects (using the DbPtr<T> class as attribute) can be treated in a similar way in the database drivers and in the database part of the library (iopcdb). Enhanced data types are also given the ability to represent NULL values. The NULL status becomes part of an attribute itself as opposed to the preceding versions of the library. Such design helps to further minimize impedance mismatch by unifying data domains of C++ data types and column types of database tables. Structure of the enhanced data type classes is displayed in Figure 5.6, “Structure of the enhanced data type classes”.
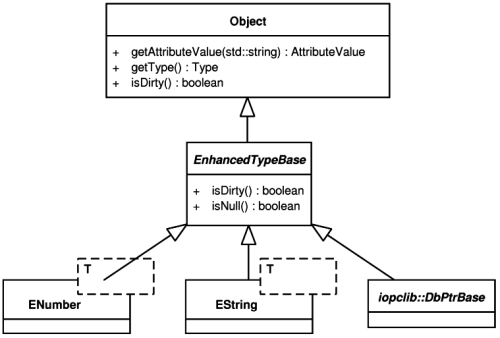
Enhanced data types are designed to be used like built-in C++ types. Example 5.4, “Enhanced datatype usage” illustrates this feature along with the NULL values and dirty status tracking.
Example 5.4. Enhanced datatype usage
EInt a = 8; a = a + 2; int b = 2 + a; EFloat d = 2.5; d = (d + 2.5 + a) / 2; EDouble c = (a + 2)*(a + 3); cout << "a: " << a << " b: " << b << " c: " << c << " d: " << d << endl; d.setNull(); cout << "a.isDirty(): " << a.isDirty() << endl; cout << "c.isDirty(): " << c.isDirty() << endl; cout << "d: " << d.toString() << endl; Output is: a: 10 b: 12 c: 156 d: 7.5 a.isDirty(): 1 c.isDirty(): 0 d: null
Modern languages like Java or languages based on the .NET platform provide language constructs that allow programmers to add custom information to class metadata. These constructs - attributes in C# or annotations in Java - have declarative meaning and do not directly impact semantics of a program. Information stored in attributes or annotations can be accessed at run-time using reflection. Class metadata concept goes well with object-relational mapping layer because the information about into which database tables to map, which mapping type to use or how the table columns should be named has also declarative character. Such information does not change at run-time.
Example 5.5. Java annotations and C# attributes
// Demonstration on the Hibernate library
// http://www.hibernate.org
// Java
@Entity
@Table(name="tab_person")
public class Person implements Serializable {
@Column(name = "name", nullable = false)
public String getName() { ... }
}
// C#
[Class(Table="tab_person")]
class Person
{
[Property(Name = "name", NotNull=true)]
public string Name { ... }
}
IOPC 2 library also implements this concept, but in a very simple way. In iopccommon there is a MetadataHolder class which, when instantiated, behaves like a dictionary. MetadataHolder can contain data of several types - integer or boolean values, void pointers or strings. Data stored in the dictionary are identified by a string key.
Classes that describe the metamodel like Type or Attribute derive from MetadataHolder. Their instances inherit the dictionary features which simulates the behaviour of the Java or .NET language constructs. However, a significant difference is that the metadata is appended at run time. It can be hardcoded into a class initialization method (see the Example 5.6, “Example usage of metadata in the IOPC 2 library” and the section called “Class metadata” for further explanation) or loaded from a configuration file during the library initialization using the supplied TextFileMetadataLoader (also described in the section called “Class metadata”).
Example 5.6. Example usage of metadata in the IOPC 2 library
class Person : public iopc::OidObject {
public:
iopc::EString name;
// the class initialization method
static void iopcInit(iopc::Type& t) {
t["db.table"].setStringValue("person");
t.getAttribute("name")["db.column"].setStringValue("name");
t.getAttribute("name")["db.type.notNull"].setBoolValue(true);
}
...
};
iopcsp is a standalone application, already introduced in the the section called “Obtaining metamodel description”. The application processes XML output of GCCXML and generates C++ files containing structures that describe classes from files originally processed by the GCCXML. To get better understanding of what the application does, we will repeat the description of the metamodel generation process in more detail:
The process is invoked on every CPP file of a user's project.[26]
GCCXML reads the input CPP file and generates a XML file describing all declarations from the input file and from all files included (it runs the C preprocessor). In the provided implementation this output file is given a filename "input-filename.cxml".
iopcsp reads the CXML file and transforms it into a couple of C++ compilable source files named "input-filename.ih" and "input-filename.ic". iopcsp searches for all descendants of the
Objectclass and for each of them it writes several lines of macro code into both IH and IC files. The macro code in the IH file expands to a full definition of theTypeDesc<T>template specialisation whereas the IC file contains the template instantiation and a static instance of aTypeRegistrarclass which registers the type by theTypeManagersingleton. The registration is initiated when the user application starts.- Last step may vary between scenarios. All IC and IH files compiled into object files can be archived using the ar program and the created archive, as a "type catalogue", can be linked to the rest of the user application. Another approach is to create archives containing the IC/IH object files together with the object files of the original input CPP sources.
The process is customisable and currently is driven by a shell script. The script can be modified by developers and even integrated into their favourite IDEs. Examples provided in this thesis illustrate how to use the shell scripts with simple Makefiles or integrated into Eclipse's CDT[27] managed build system.
Managed build system generates project build files automatically based on the project resources and user settings. Build file generation can be customized by users. Example projects provided with this thesis change the default compile command executed on each compilation unit in the project (g++) to iopc_compile.sh shell script call. iopc_compile.sh runs the steps described above these paragraphs and compiles the compilation unit using g++.
The example projects can be found on the enclosed DVD - see Appendix D, DVD content. During the managed Eclipse CDT build of the examples, a type catalogue archive is created and in the end of the build process the catalogue is lined to the resulting binary. If the examples are built using provided Makefiles, the second approach is used - type archives are created for all processed compilation units.
IOPC uses OpenC++ source-to-source translator which gives it full control over the source code structure. IOPC processes not only class declarations, but also method bodies and everything else. On the other hand, IOPC 2 uses GCCXML which processes only declarations. GCCXML output does not contain function bodies, therefore it is not possible to modify the original source code and dump the modified version into a new file that will be compiled. Such approach could work if the class declarations were in separate files and completely without any function code. This solution was however rejected as it would lead to other source code modifications and to build process complications.
Solution used in IOPC 2 is less intrusive as it generates only new structures (the type descriptions - TypeDesc<T>) into additional compilation units. It does not modify the original source code in any way and to read attribute values from reflection-capable instances it uses only "safe" C++ techniques [28]. There are two restrictions that somehow violate the usage transparency and that the developers should keep in mind when creating the reflection-capable (or persistent) classes.
The first problem is, how to access private or protected members in reflection-capable classes from the type descriptions. There are several ways how to accomplish this task, but all aside from direct memory access to these members are either not considered "safe" by the author or involve modification of the class declaration. For IOPC 2 the latter option was chosen. Developers need to include a friend class declaration as shown in Example 5.7, “Friend type description declaration” if they want to access such members via reflection or to make them persistent using the O/R mapping provided. The friend declaration should be understandable for developers as it clearly says what it does (provides access to the private members to some other entity - the reflection). It is not needed if all such members are declared as public.
Example 5.7. Friend type description declaration
class Person : public iopc::OidObject {
private:
EShort age;
EString name;
public:
void setData(std::string name, short int age) {
this->name = name;
this->age = age;
}
std::string getName() const { return name; }
short int getAge() const { return age; }
// Needed
friend class TypeDesc<Person>;
};
Second point concerns the dirty status tracking of persistent objects. All IOPC 2 library predecessors used getter and setter methods for this task. However, these methods could not be used in IOPC 2 because it would involve source code modification. For this reason, the enhanced data types were created - see the section called “Enhanced data types”. They provide automatic dirty status tracking and they can also represent the SQL NULL values. Developers do not need to use the enhanced data types if they explicitly call the Object::setDirty() method to tell the library that value of the object has changed. In contrast, if developers need to set or read NULL values using the O/R mapping, they must use the enhanced data types as there is no alternative for such task in the library.