iopclib puts together all other components into an object-relational library. It uses iopcdb with appropriate database drivers (iopcdriver_oracle10g) for database access. iopclib requires the drivers to have the object-relational features implemented and linked (the iopcdriverex_oracle10g_or extension). Metamodel description is generated using GCCXML and iopcsp and is accessed using the iopcmeta library. The iopccommon library is implicitly used by all of these components and also by iopclib itself.
iopclib defines the base classes DatabaseObject and OidObject as described in the the section called “Base classes”. The OID data type is defined by a typedef, so it can be changed in the future. Now it defaults to EULong. Identity of DatabaseObjects is expressed as instances of the KeyValues class. KeyValues contain a list of key-value pairs which represents any single-attribute or composite (multi-attribute) key.
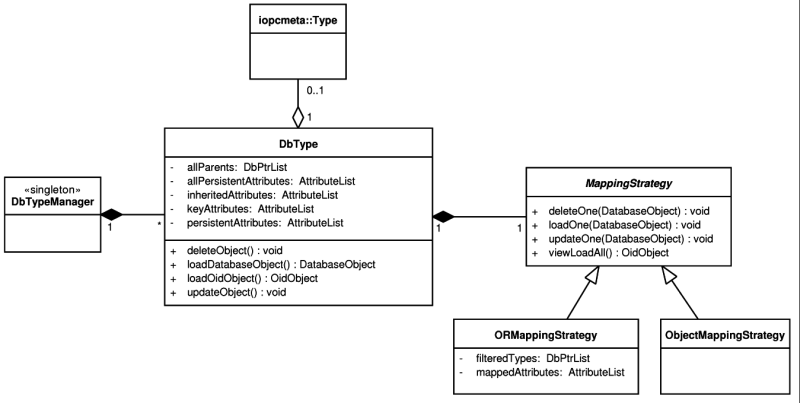
The idea behind the O/R mapping part is to wrap each type representing a persistent class[29] into a class that will provide persistence related tasks. Such class has been named DbType as displayed in Figure 5.7, “Classes involved in the database mapping process”. For each persistent class type there is exactly one DbType instance. These instances are managed by the DbTypeManager singleton.
DbType class implements the mapping algorithm described in the the section called “The mapping algorithm”. The algorithm has been split between the DbType, ObjectMappingStrategy and ORMappingStrategy classes. DbType performs the table-level part of the algorithm while the strategy classes implement the attribute-level operations - this means the Load_Object or Insert_Object[30] methods for the ADT mapping type (ObjectMappingStrategy) and Load_Row or Insert_Row[30] methods for the other mapping types (ORMappingStrategy). The lists described in the section called “Mapping algorithm prerequisites” needed by the algorithm can be found in these classes.
When one of the main CRUD methods of DbType is invoked, the program iterates through the inheritance hierarchy of the related class type according to the algorithm and calls the ObjectMappingStrategy or ORMappingStrategy to perform the attribute-level operations. The strategies in turn call the database drivers' ObjectStatementsFeature or ORStatementsFeature to generate SQL statements that will be executed. If possible, these statements are cached and not re-created each time. After that, the SQL statements are sent to the underlying DBMS via the database driver being used.
Another important class defined in iopclib is the ScriptsGenerator. ScriptsGenerator has only two methods - getDbCreateScript and getDbDrobScript. As the method names suggest, the class generates SQL CREATE and DROP scripts which create or delete database schema required by the O/R mapping. The generator first creates a list of topologically ordered persistent classes according to their inheritance dependencies and then calls the MappingStatementsFeature for each of them in order to generate the scripts. Example 5.8, “Using the ScriptsGenerator to create required database schema.” shows how to prepare required database schema.
Example 5.8. Using the ScriptsGenerator to create required database schema.
vector<string> script;
script = ScriptsGenerator::getDbCreateScript(conn->getDriver());
for(vector<string>::const_iterator it = script.begin();
it != script.end(); it++) {
conn->sqlNonQuery(*it);
}
Most classes presented in this and in the next sections are adapted from the POLiTe 2 library, so we will provide only a brief overview of their structure and of the way how they interact. For detailed description, see [03].
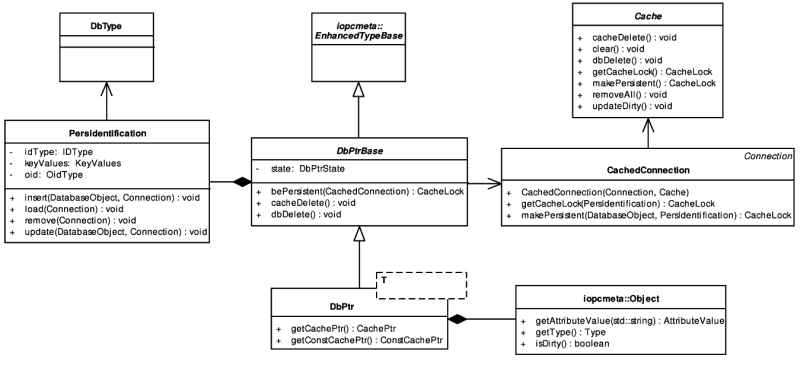
Instances of the PersIdentification class represent identity of persistent objects. The class encapsulates both the OID and the KeyValues. It also provides access to CRUD methods defined in DbType. PersIdentification instances are used as keys in the cache layer containers and in this context they represent the only communication channel between the cache layer and the O/R mapping services - see the sequence diagrams below.
As in the POLiTe 2 library, developers must use indirect references to manipulate database object in their transient or persistent state. IOPC 2 uses exactly the same concept as described in the section called “Persistent object manipulation”.
The indirect references - database pointers - are represented by instances of the DbPtr<T> template class. DbPtr<T> can point to database object instances in one of the following states:
- Transient instances which are not yet managed by a cache. The owner of these instances is the database pointer. If the pointer is destroyed before delegating the object ownership to a cache, the object is also destroyed.
- Instances managed by a cache. They may or may not already have a database representation.
-
Persistent instances that are not present in a cache. The pointer contains only their identity description (a
PersIdentificationinstance).
bePersistent is the method that transfers the object ownership to a cache. It has only one argument - a database connection (CachedConnection). The cache that is associated with this connection becomes the new owner of the object.
Example 5.9. Using the bePersistent method
// Creates a new transient Person instance // owned by the database pointer p DbPtr<Person> p; p->name = "Mary Major"; p->age = 60; // Transfers the ownership to the cache associated // with the connection conn. p.bePersistent(conn);
Example 5.9, “Using the bePersistent method” illustrates how to use the bePersistent method. First, as outlined in the Figure 5.9, “The bePersistent operation”, the transient instance is passed to a cache associated with the used connection. Then the cache takes ownership of the object and stores a reference to it into its internal structures. A CacheLock instance is returned. CacheLock class is used to lock local object copies in a cache so that they can be safely used by the user application. The local copy cannot be manipulated by the cache while it is locked.
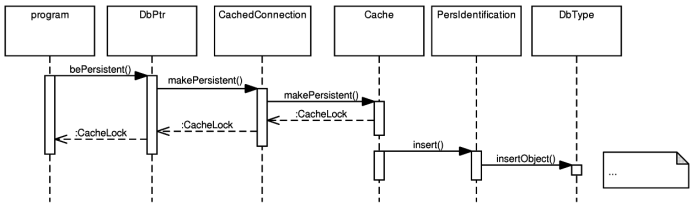
When the lock is released, the cache is free to create a persistent copy of the object in the underlying database and eventually to remove the local copy from memory. Depending on the cache implementation and updating strategy used, the actual flow of events may differ slightly.
By dereferencing a database pointer instance, or by calling one of the getCachePtr or getConstCachePtr methods, an instance of a cache pointer can be retrieved. Cache pointer can be constructed for transient as well as for cache-managed objects. If a cache pointer for a cache-managed object is created, the cache is instructed to lock (or to load from a database and lock) the object it points to (the CacheLock class is used). The lock is released as soon as the cache pointer instance is destroyed. Cache locks can also be dereferenced and, this time, a pointer to the actual database object instance is returned. The cache pointer is implemented as the CachePtr and ConstCachePtr classes. The only difference between them is that the latter one returns only a constant pointer to the object and locks it as read-only in the cache. Objects that have a read-only lock can be read by multiple threads at a time.
Both pointer classes (DbPtr<T> and (Const)CachePtr<T>) overload the -> operator. As described in the section called “Persistent object manipulation”, if a call to the operator->() function is made and if the object returned also overloads the -> operator, C++ automatically calls the operator->() on it again. Figure 5.10, “Database pointer and cache pointer interaction” illustrates what happens if the following source code excerpt is executed.
p->age = 59;
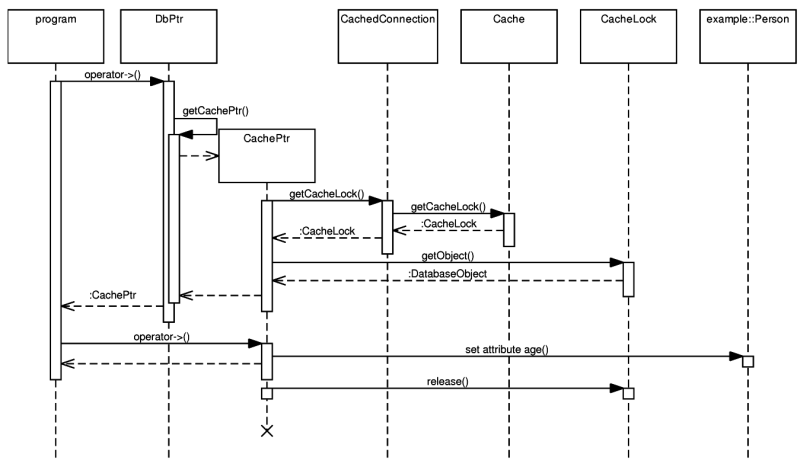
The first -> operator call results in the CachePtr<T> instance creation. Its constructor retrieves a CacheLock instance containing a reference to the locked local copy. When obtaining a CacheLock, the cache looks for the requested object in its containers and if not found, the database mapping part of the library is asked to load it from a database. Then, the object instance is locked as described above and CachePtr<T> retrieves a direct reference to the locked local copy from the CacheLock.
After that, C++ chains the operator-> call and invokes it on the newly created CachePtr<T> instance. CachePtr<T> in turn returns reference to the database object itself and the age attribute is accessed. Immediately after the assignment operation, the life cycle of the CachePtr<T> instance ends and its destructor is called. Inside the destructor, the cache lock is released.

Figure 5.11, “Interaction with the O/R mapping services” indicates how the flow of the previous scenario would continue from the getCacheLock call, if the requested object was not present in the cache. As mentioned earlier, the cache layer uses the PersIdentification class to call the database mapping routines.
The cache layer was ported from the POLiTe 2 library. Its interfaces and overall architecture remained almost unchanged. Cache layer depends on infrastructure described in the previous section. Because these infrastructure classes were preserved or enhanced, there was no reason to change the architecture of the cache layer. Again, the structure and behaviour of the cache layer were described before, so for detailed information about it please refer to [03]. Following paragraphs describe its hi-level architecture and design of its interfaces.

Each cache must implement the Cache interface. It defines following operations:
makePersistent(insert) - cache obtains ownership of a new database object. The object is made persistent according to the updating strategy and caching algorithm used. Persistent copy creation can be enforced by invoking theupdateDirtymethod.getCacheLock(load) - if needed, cache loads requested object from the database, locks it and returns a reference to it.updateDirty(update) - writes all changes including new objects to the database.updateDirtyis called fromCachedConnection.commit().dbDelete(delete) - deletes the specified object from the cache as well as from the database.clear- writes all changes to the database and removes all objects from the cache.removeAll- clears the cache, and discards all changes. Nothing is written back to the database. Called fromCachedConnection.rollback().
Classes in Figure 5.12, “Basic classes of the cache layer. VoidCache architecture.” represent the basic framework for building simple synchronous cache implementations. One such implementation is the VoidCache. The VoidCache actually does not cache anything - it merely loads and locks objects from the database as user requests. After the lock is released, changes made to the object are immediately propagated back to the database and the object removed from the cache. VoidCache stores the locked items in its containers as instances of the VoidCacheItem class.
IOPC 2 (and POLiTe 2) contains also an advanced interface designed for more complex cache implementations - the ExtendedCache interface. It adds methods that are needed by the cache manager CacheKeeper to run an asynchronous maintenance. Additionally, it allows to specify various strategies that modify behaviour of extended caches. Developers can define rules that specify which extended caches and which strategies should be used for particular objects. Architecture of the extended interface is displayed in Figure 5.13, “Extended interface of the cache layer.”.

Strategy- instances of this class can be used to modify behaviour of an extended cache. The instances represent combinations of the updating, reading, locking and waiting strategies introduced in the original POLiTe library - see the section called “Persistent object manipulation”. The class contains four of such predefined strategy combinations that can be used right away (as static instances), see [03].CacheSelectorandStrategySelector- selector interfaces are used to specify rules that decide which strategy or which cache will be used for specific objects.SimpleStratSelectorandSimpleCacheSelectorimplement these interfaces and provide basic rules which associate specific strategies or caches respectively with persistent object types. This means that the decisions are based on the processed object types.ComposedCachederives from the basic cache interfaceCacheand acts as a proxy that combines different extended caches into one "basic" cache. It usesCacheSelectorto determine which cache should be used for the object being processed.StrategySelectoris then passed to the cache where it is used to customize its behaviour.CacheKeeper- a singleCacheKeeperinstance is assigned one or more database connections. For each of these connections an instance ofComposedCacheis created.CacheKeeperprovides a facade for these caches by exposing an interface that allows developers to specify caches and strategies for particular connection and database object type combinations. However, the main benefit of usingCacheKeeperis that it runs a second thread that scans managed caches and removes instances considered as ’worst’. If dirty, these instances are written back to the database.
The library offers two caches that implement the extended interface - MapLruCache and MapArcCache. As their names suggest, they use LRU and ARC replacement policies, respectively. For detailed description please refer to [03]. There are also singlethreaded variants of these two caches (suffixed with "ST") which cannot be used in multithreaded environment and thus cannot use the asynchronous maintenance that the CacheKeeper provides.
Queries in IOPC 2 are realised as instances of the SimpleQuery and FreeQuery classes. Both classes derive from the same predecessor - the Query class as displayed in Figure 5.14, “The Query classes”. The base class declares the getSql method, whose implementation translates the query represented by the particular Query descendant instance to SQL. The Driver passed as a parameter is used in the translation process to accommodate the result to the destination SQL dialect.
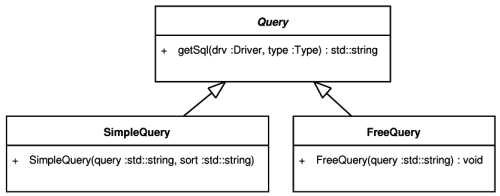
The SimpleQuery class is used to create basic queries which select data only from a single view or table specified by the result type of the query result (see below). The result can be ordered and filtered by restricting attribute values of the type. SimpleQuery is used to retrieve instances of one particular type. SimpleQuery represents only the WHERE and ORDER BY parts of the resulting SQL SELECT statement.
For more complex queries there is the FreeQuery class. This class allows developers to specify everything after the FROM keyword. There are absolutely no restrictions on joins, subselects or other SQL language constructs.
To make the queries independent from the table, view and column naming, users can insert application-level class names, attribute names and class metadata (see the section called “Class metadata”) references into any part of the query. This is probably best explained by an example:
SimpleQuery query("$::Person::name$ = 'Ian'")
The translation process looks for the dollar signs and substitutes data type and attribute names that it finds between them. The ::Person::name string will be substituted for the name of the corresponding database table/view and column. By default, the Oid object names reference the associated polymorphic views, while the non-Oid object names are replaced by the names of physical tables.
The data type and attribute names can be further expanded with class metadata codes. This way, we can force the data type name to be substituted with corresponding table name instead of its pregenerated view name:
FreeQuery query("$::Person[db.table]$ WHERE $::Person[db.table]::name[db.column]$ = 'Ian'")
The db.table and db.column class metadata are created by the iopclib library by default; however, they can be customised. For full list, see Appendix C, Metadata overview.
Results of the queries are encapsulated by the Result template class. Its only template parameter determines the type of the objects in the result set the query returns. Queries are executed by invoking the open method. After that, an iterator (ResultIterator) can be obtained and used in a standard C++ way. Example 5.10, “Example query in IOPC 2” shows how the example query from the section called “Querying” ("Find all students older than 26.") can be implemented in IOPC 2.
Example 5.10. Example query in IOPC 2
SimpleQuery q("$::Student::age$ >= 26");
Result<Student> r(conn, q);
r.open();
for (Result<Student>::iterator it = r.begin(); it != r.end(); it++) {
cout << "name: " << it->name << endl;
}